

Medium
Chat with Llama 2 Chat with Llama 2 70B Clone on GitHub Customize Llamas personality by clicking the settings button I can explain concepts write poems and code solve logic puzzles. Llama 2 pretrained models are trained on 2 trillion tokens and have double the context length than Llama 1 Its fine-tuned models have been trained on over 1 million human annotations. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Across a wide range of helpfulness and safety benchmarks the Llama 2-Chat models perform better than most open models and achieve comparable performance to ChatGPT. Meta developed and publicly released the Llama 2 family of large language models LLMs a collection of pretrained and fine-tuned generative text models ranging in..
Open source free for research and commercial use Were unlocking the power of these large language models Our latest version of Llama Llama 2. If on the Llama 2 version release date the monthly active users of the products or services made available. Llama 2 is also available under a permissive commercial license whereas Llama 1 was limited to non-commercial use Llama 2 is capable of processing. July 18 2023 4 min read 93 SHARES 69K READS Meta and Microsoft announced an expanded artificial intelligence partnership with the. July 18 2023 Takeaways Today were introducing the availability of Llama 2 the next generation of our open source large language model..
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion. Llama 2 encompasses a range of generative text models both pretrained and fine-tuned with sizes from 7. Llama 2 70b stands as the most astute version of Llama 2 and is the favorite among users. Llama 2 on Hugging Face is available in various sizes including 7B 13B and 70B. Once they grant it you can download the model using a huggingface access token. Llama 2 引入了一系列预训练和微调 LLM参数量范围从 7B 到 70B7B13B70B 其预训练模型比 Llama 1 模型有了显著改. The first thing we need to do is initialize a text-generation pipeline with Hugging Face transformers. 演示 你可以通过 这个空间 或下面的应用轻松试用 Llama 2 大模型 700 亿参数..
All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion tokens and have double the context length of Llama 1 Llama 2 encompasses a series of. As usual the Llama-2 models got released with 16bit floating point precision which means they are roughly two times their parameter size on disk see here. Model Overview Llama 2 comes in various sizes ranging from 7B to 70B parameters catering to different needs computational resources and training inference budgets. . Vocab_size 32000 hidden_size 4096 intermediate_size 11008 num_hidden_layers 32 num_attention_heads 32 num_key_value_heads None..
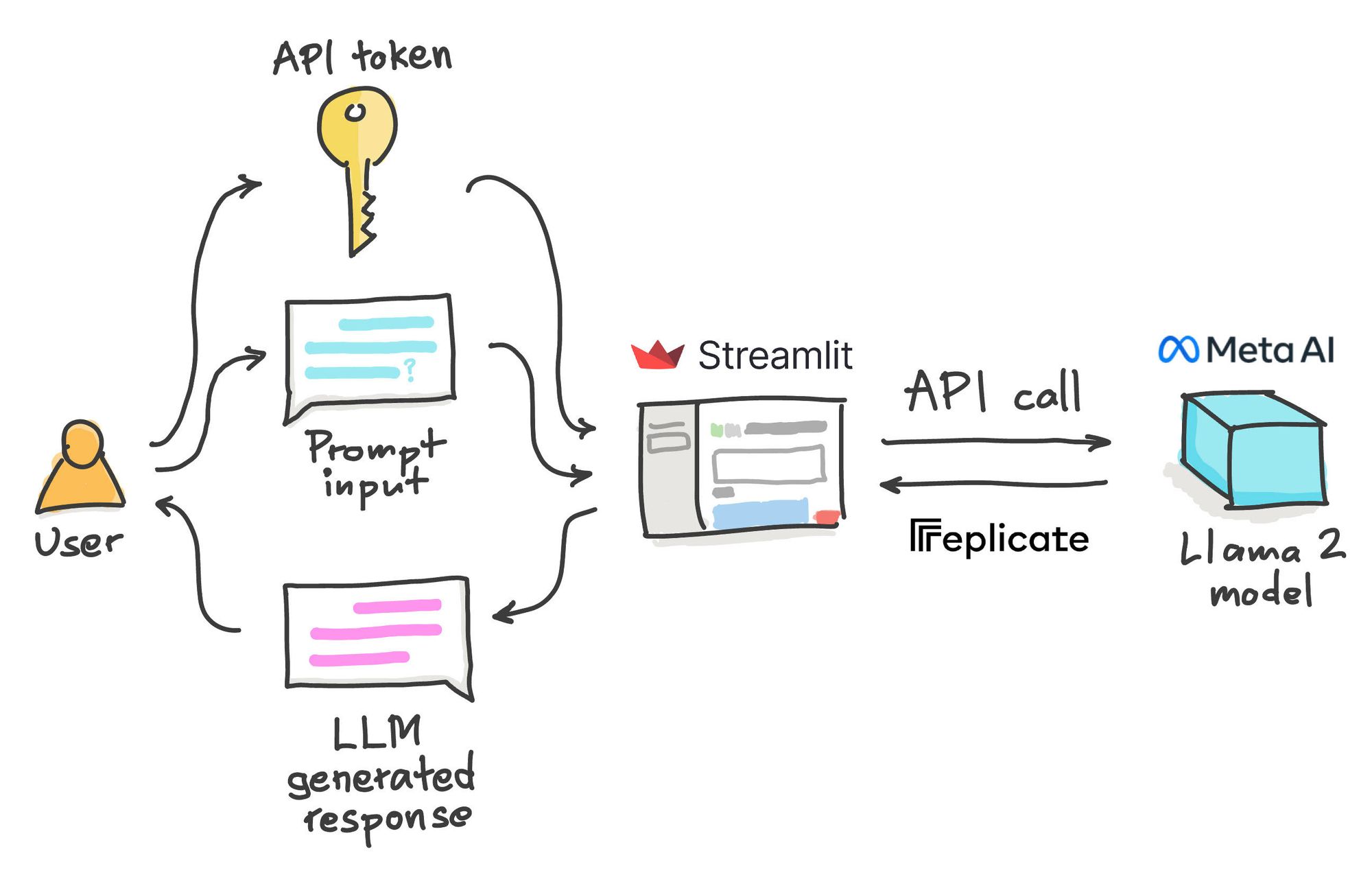
Streamlit Blog

Comments